The future of photography may be lensless
Researchers at Tokyo Tech are pioneering novel imaging technology that can create accurate photos, without the need for a lens.

Every photographer knows this truth: When it comes to cameras and gear, things can get huge—and fast. Especially in the lens department. Though mirrorless was first touted as the smaller, lighter alternative to chunky DSLRs (and in some ways, they do still hold to that promise), it’s hard to ignore the fact that these once-promising lightweight systems can quickly become bogged down with glass. And while lenses have been a part of the photographic process since, well, the very beginning, groundbreaking research by a group of scientists at the Tokyo Institute of Technology could lead to new lensless imaging systems and eventually, a lensless future.
Challenges of a lensless camera
The concept of the lensless camera isn’t entirely new. However, until now, the technology has yet to produce usable results, and the computational time needed to render the images has been too lethargic for practical use.
The current technology requires the solving of a convex optimization problem, and iterative calculations (meaning multiple results can be returned) make it a drawn-out process. But Tokyo Tech’s proposition has the possibility of making vast improvements to the process.
“Deep learning could help avoid the limitations of model-based decoding, since it can learn the model and decode the image by a non-iterative direct process instead,” the team explained on Phys.org. “Existing deep learning methods for lensless imaging, which utilize a convolutional neural network (CNN), cannot produce high-quality images. They are inefficient because CNN processes the image based on the relationships of neighboring ‘local’ pixels, whereas lensless optics transform local information in the scene into overlapping ‘global’ information on all the pixels of the image sensor, through a property called ‘multiplexing.’”

Tokyo Tech researchers propose novel technology
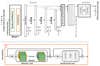
The team at Tokyo Tech has proposed a new image reconstruction method using a mathematical algorithm. The hardware consists of a mask and image sensor, with the mask encoding the incident light (light that falls on the subject), which then casts patterns on the sensor.
Looking at these patterns, the human eye would be unable to decipher any usable information—everything is rendered as incomprehensible blobs, similar to the mark left when you throw spaghetti on the wall or go Jackson Pollock on a canvas. However, the optical algorithm is able to decode the information, yielding fairly accurate results.
“Without the limitations of a lens, the lensless camera could be ultra-miniature, which could allow new applications that are beyond our imagination,” says Prof. Masahiro Yamaguchi of Tokyo Tech.
How it works
The team has pioneered a technology they call Vision Transformer (ViT), which can learn image features in what they describe as a “hierarchical” fashion, thereby avoiding the traditional CNN processing. This means direct reconstruction, with no iterative calculations needed, and a reduction in approximation errors.
Where CNN relied on local pixel information, ViT can use global features in an image. According to experiments, the process is viable and the proposed camera creates high-quality images with a processing time that would enable real-time capture.
“The ultimate goal of a lensless camera is being miniature-yet-mighty. We are excited to be leading in this new direction for next-generation imaging and sensing solutions,” says the lead author of the study, Mr. Xiuxi Pan of Tokyo Tech.
